For summer research with professor Brianna Heggeseth, we collected all the methods for clustering categorical longitudinal data we could find with R implementations in the literature and integrated them into a Shiny app that streamlined the process of running analyses using these methods.
A GitHub mirror of the project can be found here. This contains all the code needed to run the analyses. There is also a copy of the app hosted on ShinyApps.io that can be found here.
I learned how to write shiny apps for this project, as well as diving deep into the statistical literature searching for methods, then trying to find packages that implemented those methods. A full list of the methods we integrated into our app can be found on the front page of the app, but they included chi-squared distance, optimal matching distance, and mixtures of markov models.
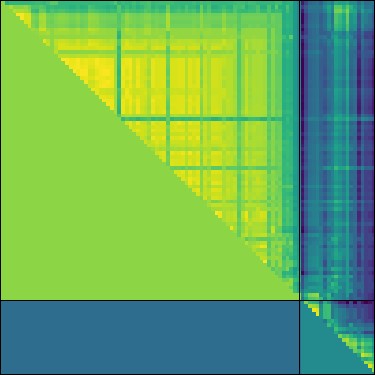
Above is an example output of a dissimilarity matrix, which shows how different elements in different clusters are from each other (yellow more different).
Below is the poster we created to present our work to other students and professors at Macalester.

A pdf can be downloaded here
Ellen Graham
Biostatistics PhD Student
I’m interested in causal inference and clinical trials for public health issues.